Organisations deal with large amounts of information daily. For this reason, predictive modelling has become a crucial tool for businesses and organisations to make informed decisions. Whether you’re forecasting sales, predicting customer churn, or anticipating equipment failures, a well-built predictive model can provide valuable insights. In this blog, we’ll explore the process of building predictive models, focusing on decision trees, random forests, and a few related techniques.
To understand how predictive models fit within the broader scope of predictive analytics, visit our Ultimate Guide to Predictive Analytics for a comprehensive overview.
What are Predictive Models?
Predictive models are tools used in machine learning and statistics to forecast future outcomes based on historical data. There are various types of predictive models, each suited to different types of data and problems. Predictive modelling is a cornerstone of data science, enabling businesses to forecast future outcomes based on historical data.
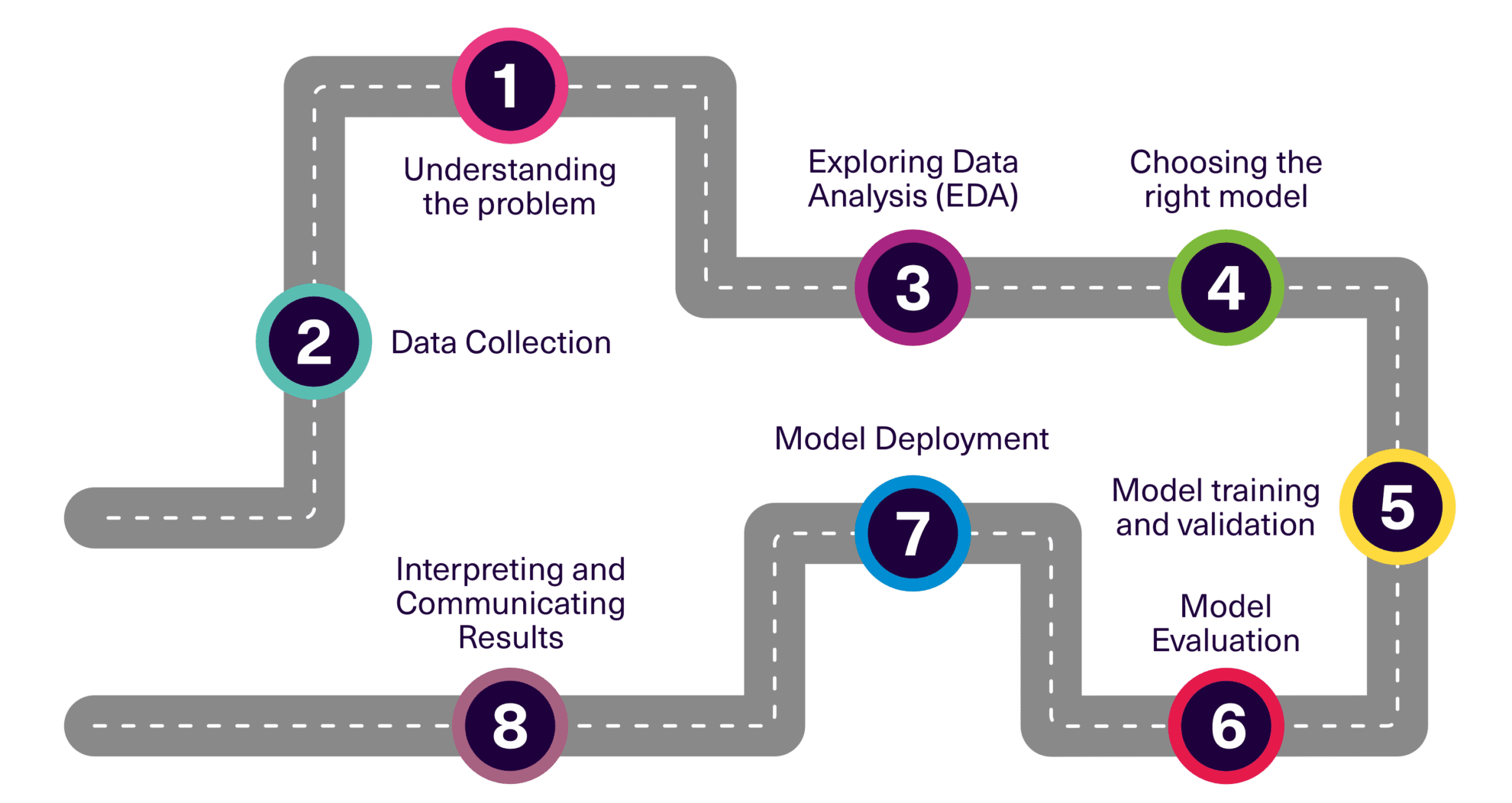
Among the various techniques available, decision trees and random forests stand out for their versatility, interpretability, and robust performance.
Understanding the Basics: Decision Trees
A decision tree is a simple, yet powerful model used for both classification and regression tasks. It works by splitting the data into subsets based on the value of input features, ultimately forming a tree-like structure of decisions.
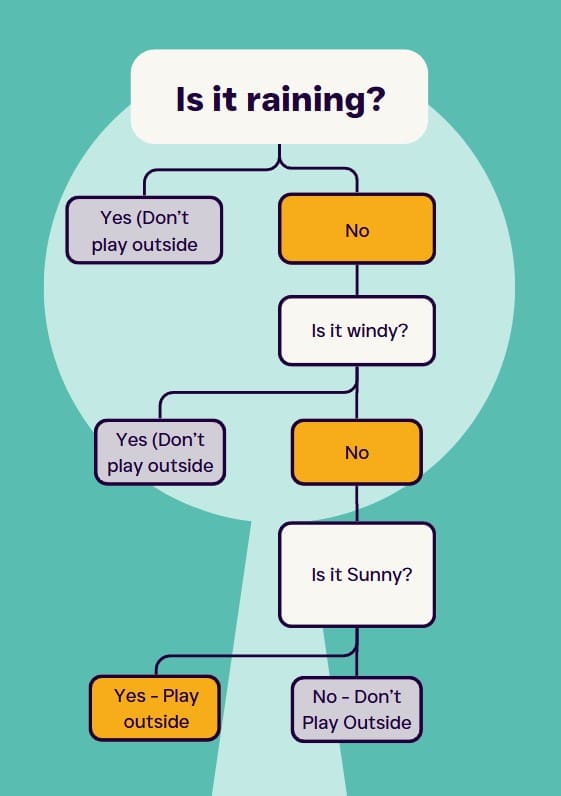
Key Concepts of Decision Trees
Here are the key observable components of a Decision Tree:
- Nodes: Represent decisions or tests on an attribute (feature).
- Edges: Represent the outcome of a decision, leading to the next node.
- Leaves: Represent the outcome (class label or predicted value).
Advantages of using Decision Trees
What are the advantages of using Decision Trees?
There are at least 2 tangible benefits of using Decision Trees:
- Interpretability: Decision trees are easy to understand and visualise, making them ideal for explaining predictions to non-technical stakeholders.
- No Need for Feature Scaling: Unlike some models, decision trees do not require features to be scaled, simplifying the preprocessing stage.
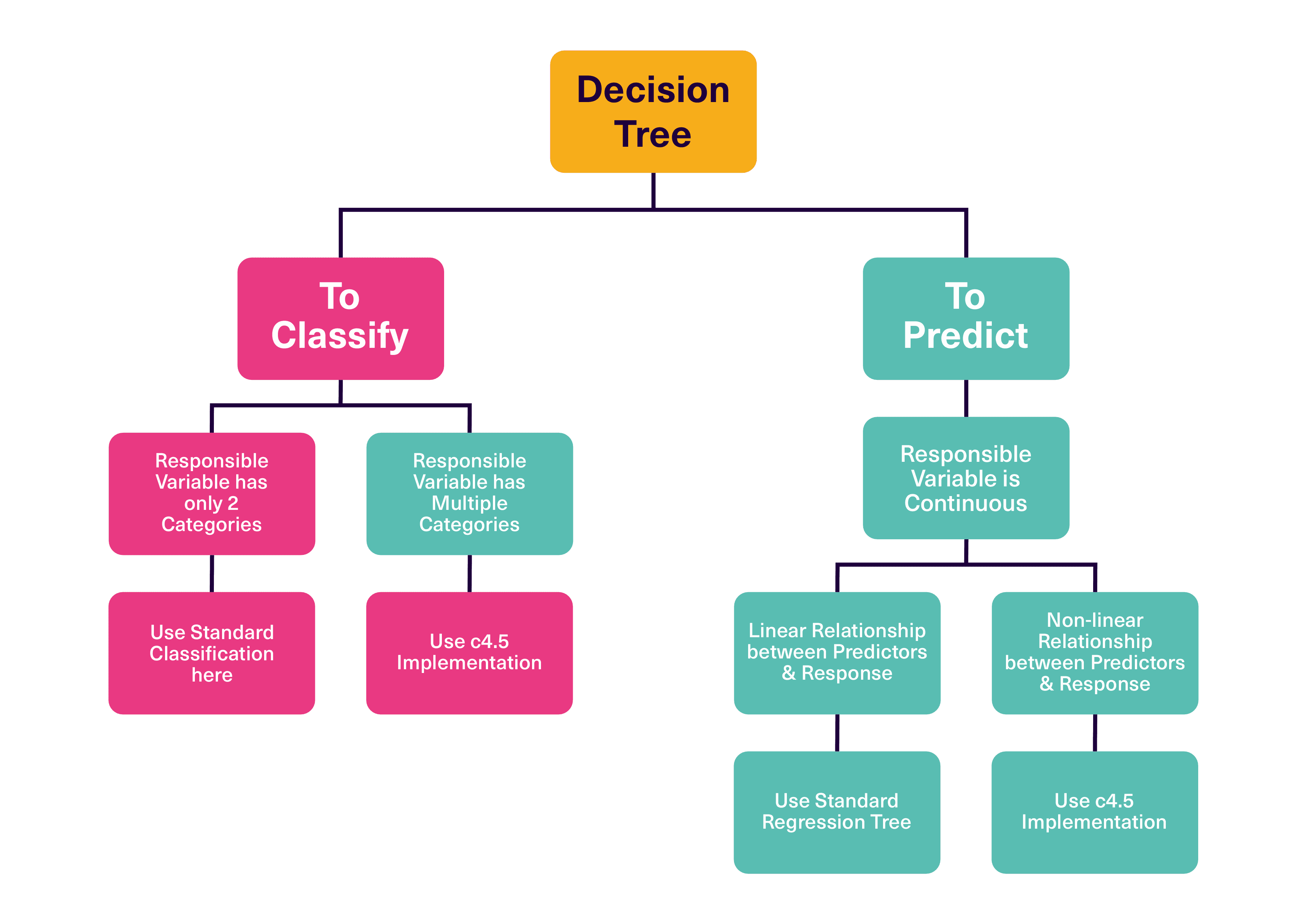
Building a Decision Tree
How can I build a useful Decision Tree?
Step 1 – Select the Best Feature: At each node, select the feature that best splits the data. Common criteria include Gini impurity (for classification) and Mean Squared Error (MSE) for regression.
Step 2 – Split the Data: Divide the dataset based on the selected feature’s values.
Step 3 – Repeat: Continue splitting until a stopping criterion is met (e.g., maximum
depth, minimum samples per leaf).
Step 4 – Pruning (Optional): Reduce the complexity of the tree by removing sections that provide
little predictive power to prevent overfitting.
Enhancing Predictions with: Random Forests
While decision trees are powerful, they can be prone to overfitting, especially with noisy data. Random forests mitigate this by building multiple decision trees and combining their outputs.
How do Random Forests Work?
Bootstrap Aggregation (Bagging): Random forests use bagging to create different training datasets by sampling with replacement from the original data.
Random Feature Selection: For each tree, a random subset of features is selected at each split, introducing diversity among the trees.
Majority Voting or Averaging: For classification tasks, the final prediction is based on majority voting among the trees. For regression, it’s the average of all tree predictions.
Advantages of using Random Forests
Reduced Overfitting: By averaging the predictions of many trees, random forests are less prone to overfitting than individual decision trees.
Feature Importance: Random forests provide estimates of feature importance, helping you understand which features contribute most to the prediction.
Building a Random Forest
Step 1 – Choose the Number of Trees: Decide how many trees to include in the forest (e.g., 100, 500).
Step 2 – Create Individual Trees: For each tree, create a bootstrapped dataset and build a decision tree using a random subset of features.
Step 3 – Aggregate the Results: Combine the predictions from all trees to make a final prediction.
Exploring Other Ensemble Techniques: Gradient Boosting and XGBoost
Random forests are just one type of ensemble model. Another powerful class of models is boosting, where trees are built sequentially, each one trying to correct the errors of its predecessor.
1. Gradient Boosting
Gradient Boosting is a powerful machine learning technique used for both classification and regression problems. It builds a strong predictive model by combining the outputs of many weaker models, typically decision trees, to improve accuracy. The idea is to fit new models to the residual errors made by previous models, reducing overall error step by step.
Sequential Learning: Unlike random forests, gradient boosting builds trees one at a time, where each tree corrects the errors of the previous one.
Weighted Trees: Trees are weighted based on their performance, with more weight given to trees that correct errors effectively.
Learning Rate: A hyperparameter that controls how much each tree contributes to the final prediction, helping to prevent overfitting.
Advantages of Gradient Boosting:
- Excellent accuracy for structured/tabular data.
- Flexibility in choosing loss functions.
- Feature importance: It provides feature importance scores, helping to understand which features are most relevant.
2. XGBoost (Extreme Gradient Boosting)
XGBoost (eXtreme Gradient Boosting) is an optimised implementation of gradient boosting that is designed to be both highly efficient and accurate. It has become one of the most popular machine learning libraries for structured/tabular data, especially in competitions like Kaggle and industry use cases.
Efficiency and Performance: XGBoost is an optimised implementation of gradient boosting that is faster and more accurate, often winning machine learning competitions.
Regularisation: XGBoost includes regularisation terms in the objective function to penalise model complexity, further reducing overfitting.
Advantages of Boosting
The advantages of “boosting” are significant in the following ways:
High Accuracy: Boosting models, especially XGBoost, often outperform other models on a wide range of tasks.
Handling Complex Data: Boosting is particularly effective with complex datasets where relationships between features and the target variable are non-linear.
3. Model Evaluation and Hyperparameter Tuning
Model evaluation is the process of assessing the performance of a machine learning model to understand how well it generalises to unseen data. It’s a critical step to ensure that the model you build is not only fitting the training data well but also performing adequately on new, unseen data. To get the best performance from your models, it’s essential to evaluate them properly and tune their hyperparameters.
Cross-Validation
K-Fold Cross-Validation is a popular technique that splits the data into K subsets (or “folds”).
The model is trained on K-1 folds and tested on the remaining fold. This process is repeated K times, with each fold used as a test set once. The results are averaged to provide a more robust evaluation.
Cross-validation helps to ensure that the model’s performance is consistent and not just specific to one train-test split.
K-Fold Cross-Validation: Split the data into K subsets, train the model on K-1 of them, and validate on the remaining one. Repeat K times, averaging the results.
Hold-Out Validation: Use a separate validation set to evaluate the model during training.
Hyperparameter Tuning
Grid Search: Test a range of hyperparameter values to find the best combination.
Random Search: Randomly select hyperparameters to test, which can be more efficient than grid search.
Automated Tuning: Tools like Bayesian Optimisation or Hyperopt can help automate and optimise the tuning process.
Deployment and Monitoring
Once you’ve built and tuned your model, it’s time to deploy it. Deployment involves integrating the model into a production environment where it can make predictions on new data.
Here are some key considerations to consider when you are deploying your model:
- Scalability: Ensure the model can handle the volume of data in production.
- Real-Time Predictions: If needed, optimise the model for real-time prediction capabilities.
- Monitoring: Continuously monitor the model’s performance to detect any drift in accuracy due to changes in data patterns over time.
Building predictive models using decision trees, random forests, and other ensemble techniques like gradient boosting is a powerful approach to solving complex problems. These models balance simplicity, interpretability, and accuracy, making them valuable tools in any data scientist’s toolkit. By following best practices in model selection, evaluation, and deployment, you can create models that not only perform well but also provide meaningful insights to drive business decisions.
If you’re interested in learning more about predictive modelling, be sure to check out:
- Predictive Modelling in Data Analysis: Get an overview of predictive modelling, its importance, and its applications across industries.



